

Як автоматизувати отримання виписки з Монобанки для благодійних організацій
Сьогодні “МоноБанка” — один з найвідоміших інструментів для благодійників. МоноБанки знають всі, і цьому сервісу довіряють більше, ніж іншим.
Якщо для рядового користувача створення і адміністрування монобанки не є складним, то для юридичних осіб це досить складний процес, а користування банківським сервісом на стороні Універсалбанку іноді перетворюється на справжнє пекло.
Коли з однодумцями створили благодійний фонд, я взявся за проектування автоматизації процесів, щоб все було зручно. І я очікував труднощів де завгодно, але точно не від Монобанку. Та коли почав занурюватися в це, то зрозумів, що ця структура як декорація в кіно, на екрані все виглядає гарно, а за його межами — картонні декорації. І всі ці косяки намагається згладжувати служба підтримки Моно, активно комунікуючи з користувачами. Вона дійсно старається, але не всесильна. Адже там, де закінчується Моно, починається Універсалбанк, і тут вже з’являється присмак нафталіну, а по більшості сервісів — їдкий трупний запах Legacy…
Як працює виписка по МоноБанці для звичайного користувача? Ви відкрили додаток, створили банку і можете дивитися хто донатить, у реальному часі. А знаєте, як це працює для юр. осіб через додаток? … а ніяк не працює :-)). Немає цього функціоналу в додатку! 🙂
Виписки по монобанці приходять щодня на…. електрону пошту, яка була вказана при реєстрації. Ну благо що не на поштову скриньку Укрпошта 🙂 Ніякого API немає, хоча для фізосіб та ФОПів у Монобанку API є і він нормальний. Але через МоноAPI ніяк не достукатися до монобанки фонду, бо це вже територія Універсалбанку!…
А ЩО ТАКЕ УНІВЕРСАЛБАНК ПО IT-СЕРВІСАМ? ОСЬ З ЦЬОГО МІСЦЯ ВМИКАЙТЕ УЯВУ:
Уявіть постапокаліптичну пустелю зі звалищем техніки, засипаною віковим пилом, десь завиває вітер і перекочується перекотиполе. Зліва стоїть напівржавий шкільний автобус, з американських фільмів, із старими дротами витої пари. З автобусу видивляється дуже втомлений, бородатий чоловік у подертих речах зі старою клавіатурою в руках. У вікні автобуса видно облаштовані робочі місця зі старими кінескопними моніторами з 90-х.
В цьому автобусі живуть програмісти Legacy коду, а в кадрі їх техлід, якого кредитами та іпотеками для співробітників тримають тут з 90х років. За автобусом розташований великий цвинтар, який тягнеться вдалечінь, з могилами, до яких ведуть дроти витої пари з автобуса. Це цвинтар Legacy коду, який ці програмісти намагаються підтримувати. А на задньому плані можна побачити яскравий, сучасний парк розваг під назвою Mono Park 🙂
Десь так я собі уяввляю всю цю компанію, коли зтикаюсь з їх ИТ-сервісами. А ось так це намалював штучний інтелект Dall-E. Мені здається влучно:)

Вибачте, відволікся. Так от, ці виписки по монобанці приходять вам на електронну пошту, а щоб ви взагалі не відчували себе людиною, вони приходять заархівовані у ZIP, в якому всього один файл у форматі CSV. “Зручно”, правда?
Традиційно, потурбувавши службу підтримки Монобанку з приводу пошуку більш сучасного і зручного рішення для експорту виписки, і не знайшовши його, я сів писати код, який би швидко вирішив задачу бо багато часу на це немає.
Що мені було потрібно:
- Кожного разу, коли приходить лист з випискою, вилучити дані та додати їх до бази даних.
- Сформувати звіт по конкретній банці збору за певний період у форматах PDF та JSON.
- Отриманий JSON відправити POST-запитом на сайт, щоб розмістити на веб-сторінці збору перелік донатів та коментарі від небайдужих людей, за що величезна їм подяка!
Нижче я надам дуже стислий код, який виконує ці функції, але замість запису в базу даних, дані будуть збережені у файл.
Скрипт виконує:
- Підключення до поштового сервера за допомогою IMAP для вилучення листів із вкладеними ZIP-файлами.
- Розпаковка ZIP-архівів та вилучення CSV-файлів.
- Фільтрація даних за певним критерієм (наприклад, по полю “Референс”).
- Відправка даних на сервер за допомогою POST-запиту в форматі JSON.
- Генерація звітів у форматі CSV та PDF.
Необхідні бібліотеки Python:
pip install imaplib email zipfile pandas fpdf requests numpy
Повний скрипт виглядає так:
import imaplib
import email
import zipfile
import pandas as pd
from io import BytesIO
from datetime import datetime, timedelta
import json
import requests
from fpdf import FPDF
import numpy as np
# Email account details (replace with your actual data)
IMAP_SERVER = 'mail.yourdomain.com'
IMAP_PORT = 993
EMAIL_ACCOUNT = 'your_email@yourdomain.com'
PASSWORD = 'your_password'
# URL for the POST request to send data to the server
POST_URL = 'https://yourdomain.com/your_script.php'
# Authorization token (replace with your actual token)
AUTH_TOKEN = 'your_secure_token'
# Reference filter for data selection (if empty, all data will be selected)
REFERENCE_FILTER = 'F_966' # You can replace this or leave it empty
# Connect to the email server using IMAP
mail = imaplib.IMAP4_SSL(IMAP_SERVER, IMAP_PORT)
mail.login(EMAIL_ACCOUNT, PASSWORD)
mail.select('inbox')
# Search for emails from a specific sender over the last month
today = datetime.today()
since_date = (today - timedelta(days=30)).strftime("%d-%b-%Y")
status, email_ids = mail.search(None, f'(FROM "SENDER_EMAIL@monobank.com" SINCE {since_date})')
# Check if any emails were found
if email_ids[0]:
print(f"Emails found: {len(email_ids[0].split())}")
else:
print("No emails found.")
# List to store combined data
all_data = []
# Process each email
for e_id in email_ids[0].split():
status, email_data = mail.fetch(e_id, '(RFC822)')
for response_part in email_data:
if isinstance(response_part, tuple):
msg = email.message_from_bytes(response_part[1])
print(f"Processing email: {msg['Subject']}")
# Process each part of the email
for part in msg.walk():
if part.get_content_maintype() == 'multipart':
continue
if part.get('Content-Disposition') is None:
continue
# Look for zip attachments
filename = part.get_filename()
if filename and filename.endswith('.zip'):
print(f"Found archive: {filename}")
# Process each zip file found
zip_data = BytesIO(part.get_payload(decode=True))
try:
with zipfile.ZipFile(zip_data, 'r') as zip_ref:
for file in zip_ref.namelist():
if file.endswith('.csv'):
print(f"Extracted file: {file}")
# Read each CSV file from the archive using UTF-8 encoding
with zip_ref.open(file) as csv_file:
data = pd.read_csv(csv_file, encoding='utf-8')
# Filter data by reference if REFERENCE_FILTER is set
if REFERENCE_FILTER:
filtered_data = data[data['Референс благодійної банки'] == REFERENCE_FILTER]
else:
filtered_data = data
# Convert the data to a list of dictionaries and add to combined list
all_data.extend(filtered_data.to_dict(orient='records'))
except zipfile.BadZipFile:
print(f"Error opening archive: {filename}")
# Check if there is any data to save
if all_data:
# Export to CSV
combined_df = pd.DataFrame(all_data) # Create DataFrame from combined data
combined_df.to_csv('combined_data.csv', index=False, encoding='utf-8') # Save as CSV
print("Data successfully saved to 'combined_data.csv'.")
# Function to clean data before sending
def clean_record(record):
"""Replace invalid NaN or infinite values with 0."""
for key, value in record.items():
if isinstance(value, float):
if np.isnan(value) or np.isinf(value):
record[key] = 0 # Replace NaN or infinity with 0
return record
# Clean all data records
all_data = [clean_record(record) for record in all_data]
# Send the cleaned data to the server via POST request
headers = {
'Authorization': f'Bearer {AUTH_TOKEN}',
'Content-Type': 'application/json'
}
# Convert the data to JSON
json_data = json.dumps(all_data, ensure_ascii=False, indent=4)
# Send data to the server
response = requests.post(POST_URL, data=json_data.encode('utf-8'), headers=headers)
if response.status_code == 200:
print("Data successfully sent to the server.")
else:
print(f"Error sending data: {response.status_code} - {response.text}")
# Export data to PDF
pdf = FPDF(orientation='L', unit='mm', format='A4') # Landscape orientation
pdf.add_page()
# Add fonts (replace the path with your actual font files)
pdf.add_font('Roboto', '', './Roboto/Roboto-Regular.ttf', uni=True)
pdf.add_font('Roboto', 'B', './Roboto/Roboto-Bold.ttf', uni=True)
# Set font for title
pdf.set_font('Roboto', 'B', 14)
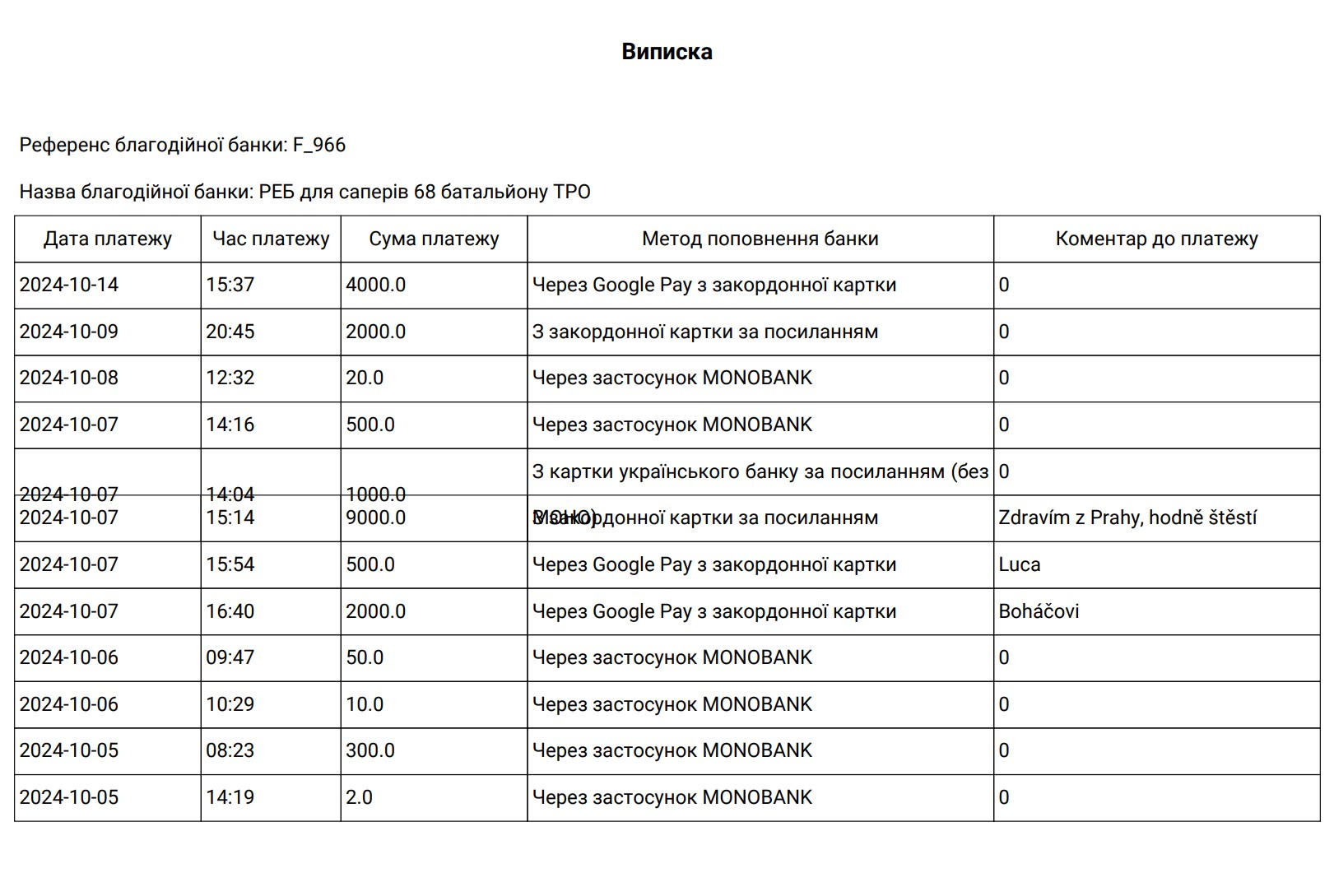
pdf.cell(280, 10, txt="Виписка", ln=True, align='C')
# Include "Reference" and "Bank Name" only once before the table
pdf.set_font('Roboto', '', 12)
reference_value = all_data[0].get("Референс благодійної банки", "")
bank_name = all_data[0].get("Назва благодійної банки", "")
pdf.ln(10)
pdf.cell(280, 10, f"Референс благодійної банки: {reference_value}", ln=True)
pdf.cell(280, 10, f"Назва благодійної банки: {bank_name}", ln=True)
# Define columns to include and their widths
columns_to_include = ['Дата платежу', 'Час платежу', 'Сума платежу', 'Метод поповнення банки', 'Коментар до платежу']
col_widths = [40, 30, 40, 100, 70] # Set column widths
# Print table headers
for i, column in enumerate(columns_to_include):
pdf.cell(col_widths[i], 10, txt=column, border=1, align='C')
pdf.ln()
# Print rows with a combination of cell() and multi_cell()
for record in all_data:
row_height = 10 # Default row height
# Calculate max line count for each cell
line_counts = [
pdf.get_string_width(str(record['Дата платежу'])) // col_widths[0] + 1,
pdf.get_string_width(str(record['Час платежу'])) // col_widths[1] + 1,
pdf.get_string_width(str(record['Сума платежу'])) // col_widths[2] + 1,
pdf.get_string_width(str(record['Метод поповнення банки'])) // col_widths[3] + 1,
pdf.get_string_width(str(record['Коментар до платежу'])) // col_widths[4] + 1
]
max_lines = max(line_counts) # Calculate the maximum line count in the record
# Adjust row height based on the maximum line count
row_height = 10 * max_lines
# Print regular columns using cell()
pdf.cell(col_widths[0], row_height, txt=str(record['Дата платежу']), border=1)
pdf.cell(col_widths[1], row_height, txt=str(record['Час платежу']), border=1)
pdf.cell(col_widths[2], row_height, txt=str(record['Сума платежу']), border=1)
# Use multi_cell for long text in "Метод поповнення банки" and "Коментар до платежу"
x, y = pdf.get_x(), pdf.get_y() # Save current coordinates
pdf.multi_cell(col_widths[3], row_height / max_lines, txt=str(record['Метод поповнення банки']), border=1)
# Move to the next column
pdf.set_xy(x + col_widths[3], y)
# Update coordinates for "Коментар до платежу"
x, y = pdf.get_x(), pdf.get_y()
pdf.multi_cell(col_widths[4], row_height / max_lines, txt=str(record['Коментар до платежу']), border=1)
pdf.set_xy(x + col_widths[4], y)
# Move to the next row
pdf.ln()
# Save the PDF
pdf.output("combined_data.pdf")
print("Data successfully saved to 'combined_data.pdf'.")
else:
print("No data found.")
# Close the email session
mail.logout()
Code language: PHP (php)Тепер прокоментую.
Дані для підключення до поштового сервера: Тут вкажіть ваші реальні дані поштового сервера, обліковий запис і пароль.
IMAP_SERVER = 'mail.yourdomain.com'
EMAIL_ACCOUNT = 'your_email@yourdomain.com'
PASSWORD = 'your_password'
Code language: JavaScript (javascript)URL для POST-запиту: Тут я задаю URL сервера, куди скрипт буде відправляти json з даними.
POST_URL = 'https://yourdomain.com/your_script.php'
Code language: JavaScript (javascript)Токен авторизації: Щоб скрипт на сайте не задовбували якісь боти, я використовую токен який відправляю в запиті.
AUTH_TOKEN = 'your_secure_token'
Code language: JavaScript (javascript)Ось тут унікальний ID банки. Якщо у вас багато зборів то якось їх потрібно розділяти. В мене реалізовано так- якщо вказаний ідентифікатор то філтруємо, якщо поле порожнє то відображаємо всі.
# Reference filter for data selection (if empty, all data will be selected)
REFERENCE_FILTER = 'F_966' # You can replace this or leave it empty
Code language: PHP (php)Ось тут ми задаємо електрону адресу з якої Моно буде присилати виписку, та задаю за який період обробляти листи. Для прикладу беру 1 місяць.
# Search for emails from a specific sender over the last month
today = datetime.today()
since_date = (today - timedelta(days=30)).strftime("%d-%b-%Y")
status, email_ids = mail.search(None, f'(FROM "SENDER_EMAIL@monobank.com" SINCE {since_date})')
Code language: PHP (php)Наче і все. Результат виводжу в PDF, але сильно з форматуванням документу я не парився. Для моїх задач цього було достатньо.
Цей скрипт працює в мене в CRON і запускається кожного дня в 11:00
0 11 * * * /usr/bin/python3 /path_to_your_script/your_script.py
Code language: JavaScript (javascript)У мене все!
Дякую за увагу і сподіваюся, що інформація була корисною!



